Technical SEO features
Are you surprised that 12 out of the 21 SEO-friendly features on this list are in this category?
That’s probably a good thing because it means that you’ve come to expect many of these features as a core part of any CMS.
Luckily, many systems do provide most (if not all) of these features. It’s nonetheless important to check before choosing a CMS, as many of these can make or break your SEO efforts.
#6 - Crawlability and indexability of your content
Did you ever stop to make sure that search engine crawlers like Googlebot can crawl all of your pages and index its content properly?
Probably not. It’s not really on top of many SEO checklists out there. That's a shame though, as I would argue it should be at the top of your list for any technical SEO audit you do. It's that important.
Admittedly, issues with crawlability and indexability are rare and for most websites (and content management systems) it’s not an issue. But when there are issues, these can result in devastating losses in search traffic and rankings.
That’s why you should make sure that your website follows best practices on how it makes your content available to crawlers. Can crawlers access your website content? And when they access your website, can they crawl the content on your pages, so it’s properly added to the search index?
The best way to answer those questions is to first look at whether crawlers can access your site (crawlability) and next to look at how your content is made available to web crawlers (indexability).
Crawlability
An easy way to test crawlability is to use Google Search Console and test out your URLs. If they are blocked from being crawled, you’ll get an error back like the one below:
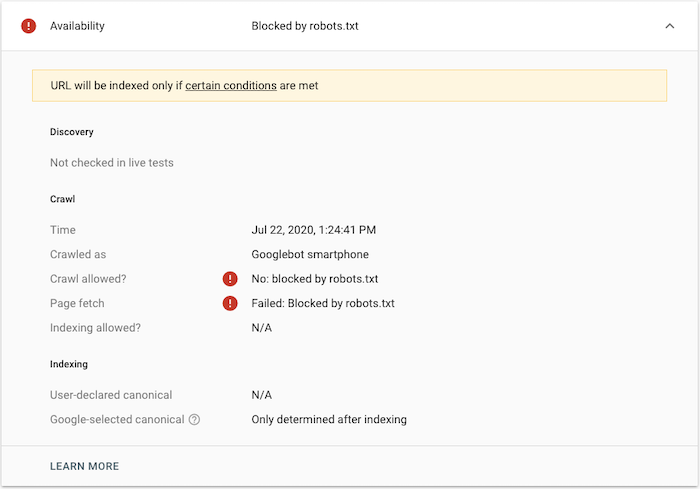
If your page is blocked (and shouldn’t be) you should have a look at your robots.txt file (see next feature for more details). And if the issue is something different, well, then you have some troubleshooting to do.
Indexability
Once you’ve ensured that Google can crawl your website content, it’s important to look at 2 things:
- If your page is getting indexed
- And how much of your content it actually puts into the index
Most SEO audits focus on whether or not a page is in the index, but not if Googlebot crawled all of the page or only parts of it. To understand why this is so important, it’s good to know how Google serves its search results.
For that, you should look at this video by Google (yes, it’s old, but still relevant since the fundamentals of crawling and indexing have not changed).
So how do you ensure that all of your content is indexed correctly?
You make sure that the content is served in a way that is easy for crawlers to process.
This might sound very technical, but it really isn’t. Take a look at the source code of your page; can you find your content if you search for it?
In most cases, your content will be served through clean HTML and will be present in the source code. If that’s the case for you, then you should be good to go.
If your content can’t be found or is served through Flash, frames, or something other than HTML, then you might be in trouble. To check if Google can actually crawl and index the content of your page, you should test it. Here are 2 quick ways to do so:
- Use Google Search Console’s “Inspect URL” feature and test the live URL of the page. Now you’re able to see a screenshot of what was crawled as well as the HTML that Google found. If your content is found in the HTML that Google returned here, then it’ll be in the index as well.
- Make a phrase match search on Google by copying a paragraph from your page and putting it in quotation marks in a Google search (ie. “pasted content paragraph here”). If your site does not appear in the results, then your site could have indexability issues hurting your SEO.
So what about serving content through JavaScript - is that bad?
You might have heard that Google can’t crawl content if it’s added through JavaScript. That is no longer the case.
That being said, you should be cautious and test more often if your website relies on JavaScript for serving content. As you can see in the figure below, crawling and indexing JavaScript content is done; but it requires an extra step for Googlebot: rendering.
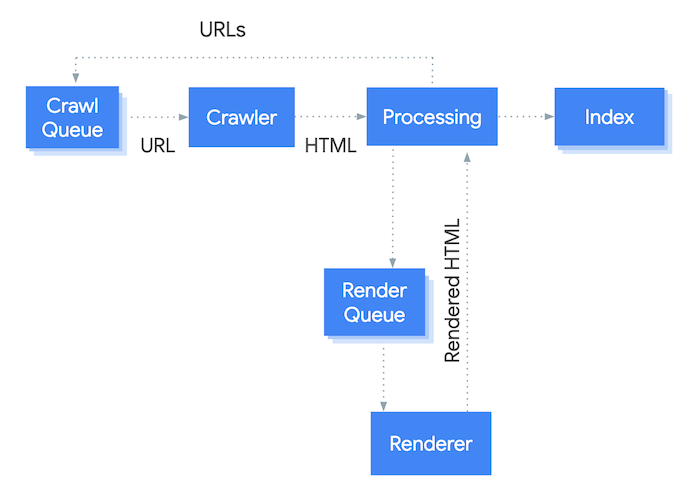
So if your website is relying on JavaScript content you might have to wait longer before Google updates the content they have in their index, as it takes them longer to process. It also requires additional resources, which might further limit your crawl budget.
On umbraco.com we do use JavaScript to serve some of our content, so the above is not to scare you away from using it. It's mostly a word of caution so you're sure to check that the content is rendered properly and you're not losing SEO value on your pages.