Codegarden
Don’t miss Umbraco’s event of the year
Get your ticket →
Book a discovery call
Products
Products
CMS
Data Orchestration
Heartcore
Umbraco for Enterprise
Services
Managed Cloud
Support
Training
Capabilities
AI Integration Tools
Personalization & Analytics
E-commerce & Payments
Content Workflows
Forms & Data Collection
Deployment & Syncing
UI Builder
Marketplace
Solutions
Customers
Case Studies
Umbraco by Industry
Partners
Find a Partner
Become a Partner
Log in
Pricing
Resources
Learn
Blog
Develop
Documentation
Product Roadmap
Release Cadence
GitHub
Connect
Community
Events
Forum
Company
About
About Us
Our Values
Sustainability
Trust Center
Contact
Contact us
Work at Umbraco
Book a discovery call
The Agent-Ready CMS: Introducing Agent Skills: Umbraco Backoffice Extension
From turning rough ideas into working wireframes to building complex backoffice extensions without hallucinations, discover how we’re making AI a practical tool for Umbraco development.
March 16, 2026
Top story
uProfile March 2026 - Debasish Gracias
On a mission to inspire, connect, and bring together the global Umbraco community
March 13, 2026
Umbraco Product Update - Q1 2026
Explore this update featuring the launch of Umbraco Compose, a new AI strategy, enhanced security in Umbraco Cloud, and a new era for Search.
March 12, 2026
Umbraco CMS Security Advisory, March 10, 2026
Security patches are available for Umbraco versions 16 and 17 to fix three moderate-to-high vulnerabilities. Upgrade now to secure your CMS. Projects on Umbraco Cloud will automatically receive the fixes.
March 10, 2026
How to Audit Umbraco Content for AI References (AEO / GEO Readiness)
A practical Umbraco guide to AEO/GEO: how to structure content so AI systems can find, extract, and reference the right sections.
March 5, 2026
The Agent-Ready CMS: What are Agent Skills?
Discover how Agent Skills and MCP are transforming Umbraco into an Agent-Ready CMS. Learn to power intelligent actions and future-proof your agency's workflow.
March 3, 2026
uProfile February 2026 - Jenny Bradshaw
Meet Jenny Bradshaw - From "Um-WHAT?" to Umbraco MVP
February 17, 2026
Announcing: Umbraco Contributing Partners 2025
64 Platinum & Gold Partners have earned the badge of being this year's Contributing Partners
February 13, 2026
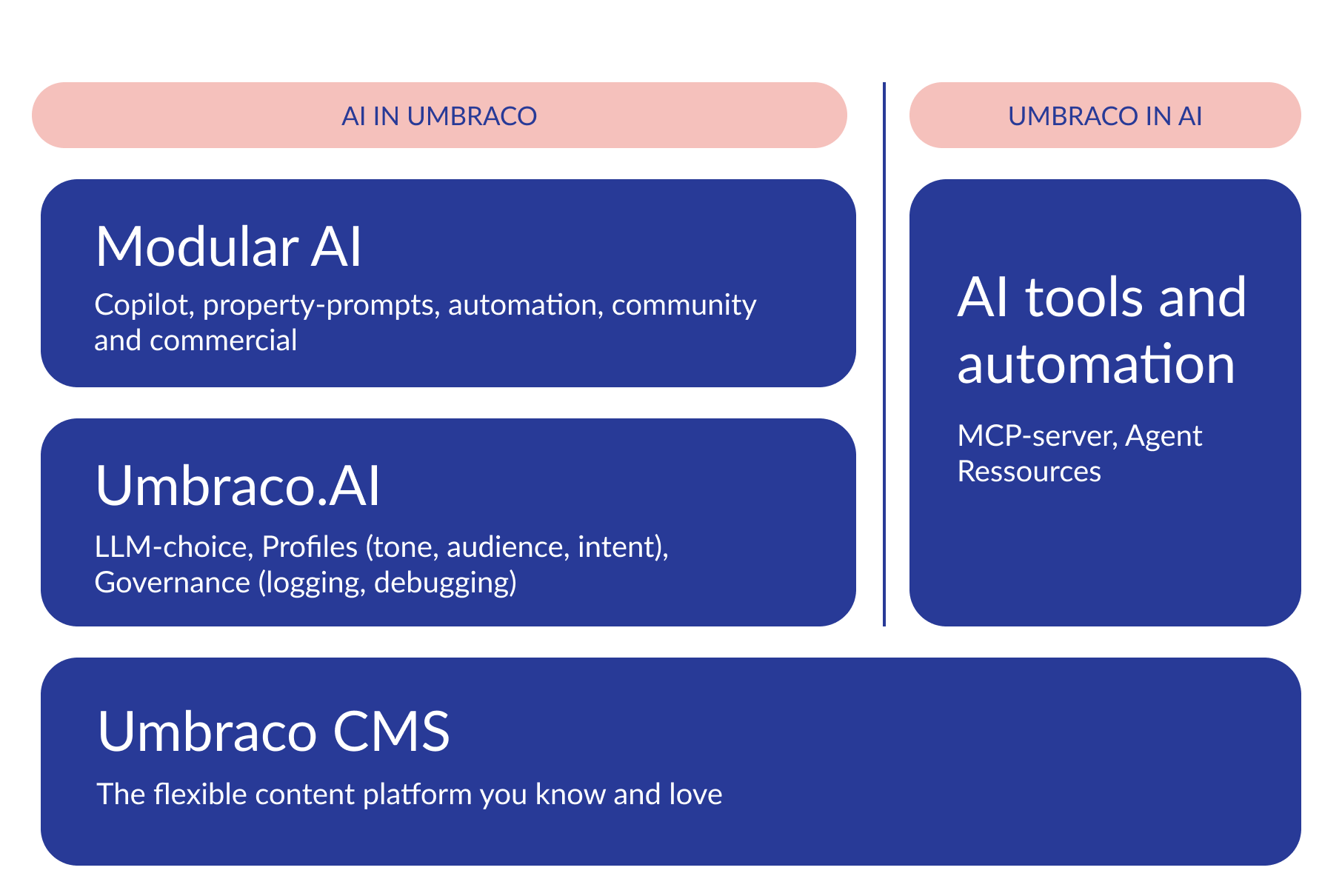
AI, intentionally
Discover how Umbraco is building AI with purpose, putting choice, governance, and long-term value at the centre of digital experiences.
February 5, 2026
Introducing Umbraco Compose
We’re proud to launch our new Data Orchestration Platform: Umbraco Compose. A platform that’ll ease the management of data flows in complex enterprise projects. Discover how Compose can save you hundreds of development hours and struggles.
February 3, 2026
Umbraco's product organisation achieves ISO 27001 certification
The Umbraco product organisation achieves ISO 27001 certification to strengthen security and enterprise readiness.
January 23, 2026
First
Previous
1
Next
Last
Categories
Community
Events
Open Source
Partners
Products
Security
Technical
Umbraco HQ
Tags
.NET 5
.NET 6
.NET 7
.NET core
A/B Testing
Accessibility
AEO
AI
Automation
Autumn Contribution Challenge
backoffice
Bellissima
CMS
CODECABIN
codegarden
coding pirates
Commerce
community
Composable
Composable DXP
Compose
content editing
Conversion rate optimization
Courier
cro
Deep Dive
Deploy
development
documentation
Engage
Festivals
Forms
frontend
G2
GEO
gold partners
hacktoberfest
Headless
LLM
marketing
marketplace
MCP
meetups
MVP
new hires
open source
Orchestration
package
partners
Personalization
Product Update
pull requests
Search
security
SEO
sustainability
Thought leadership
training
UI Builder
UI Library
umbraco 10
umbraco 11
Umbraco 12
Umbraco 13
Umbraco 14
Umbraco 15
Umbraco 16
umbraco 17
umbraco 7
umbraco 8
Umbraco 9
umbraco cloud
Umbraco Compose
Umbraco Forms
umbraco heartcore
Umbraco Learning Base
Umbraco Uno
uProfile
US Summit
Webinar
workflow